

Cet article a pour but de parcourir quelques applications intéressantes des transformers, la tendance en Deep Learning, que j'ai pu rencontrer dans certaines publications scientifiques récentes.

Qu'est ce que c'est ?
Pour rappel, il s'agit d'une catégorie de modèles de Deep Learning très efficaces dans le domaine du Traitement du Langage Naturel (NLP). Ils ont été introduits en 2017 par Google dans l'article de recherche Attention is all you need.
Depuis de nombreux travaux ont été publiés sur ce sujet, et ont donné lieu à une variété de modèles basés sur les transformers pouvant accomplir de multiples tâches en NLP mais également dans le domaine de la vision par ordinateur.
Le but de cet article n'étant pas d'expliquer le fonctionnement des transformers, nous en présenterons néanmoins rapidement le principe. Il existe en effet, une multitude d'articles qui le font très bien, ainsi que le mécanisme d'attention sur lequel ils reposent.
Considérons la traduction d'un texte du français à l'anglais. Les réseaux de neurones récurrents représentent l'état de l'art pour la plupart des tâches NLP dont la traduction d'un texte. La problématique dans le traitement séquentiel (le modèle prend le texte en entrée mot par mot), est la difficulté à paralléliser l'exécution du modèle.
Par ailleurs, le schéma classique est d'utiliser une partie d'encodage, dont le but est de modéliser ce qui caractérise la séquence entrée, puis une partie de décodage, qui elle traduit cette représentation dans la langue voulue.
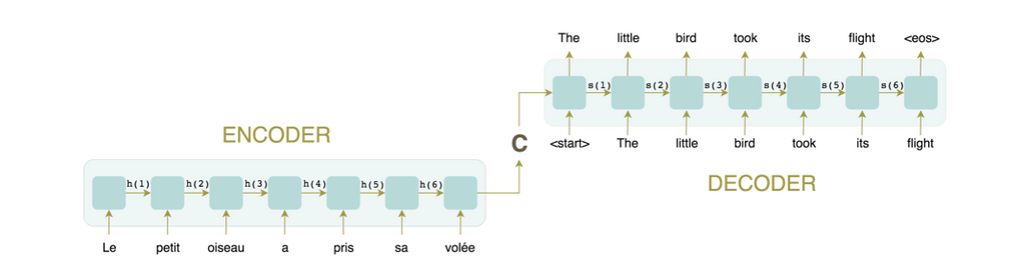
Comme le montre le schéma ci-dessus, le lien entre la partie encodage et décodage repose sur un vecteur. Celui-ci est censé contenir toutes les informations pertinentes du texte. Ce qui limite les possibilités de modélisation des relations de dépendance présentes dans le texte, cela est d'autant plus vrai que la séquence est longue. Pour pallier ce problème, le mécanisme d'attention a été mis en place.
Le mécanisme d'attention consiste à imiter l'attention de l'esprit.
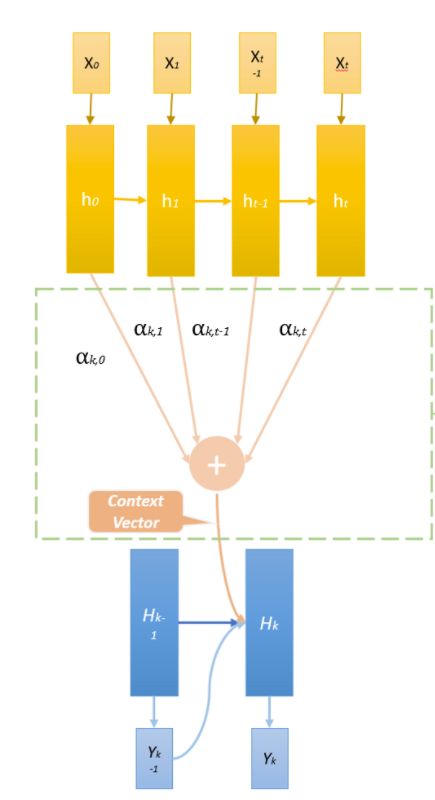
En utilisant un réseau de neurones d'une seule couche, entièrement connectée, avec des poids qui vont changer à chaque pas de temps, on donne alors au modèle la faculté de se concentrer sur une partie ou une autre du texte en fonction de son avancement dans le traitement de la séquence.
Les transformers reposent uniquement sur ce mécanisme d'attention.
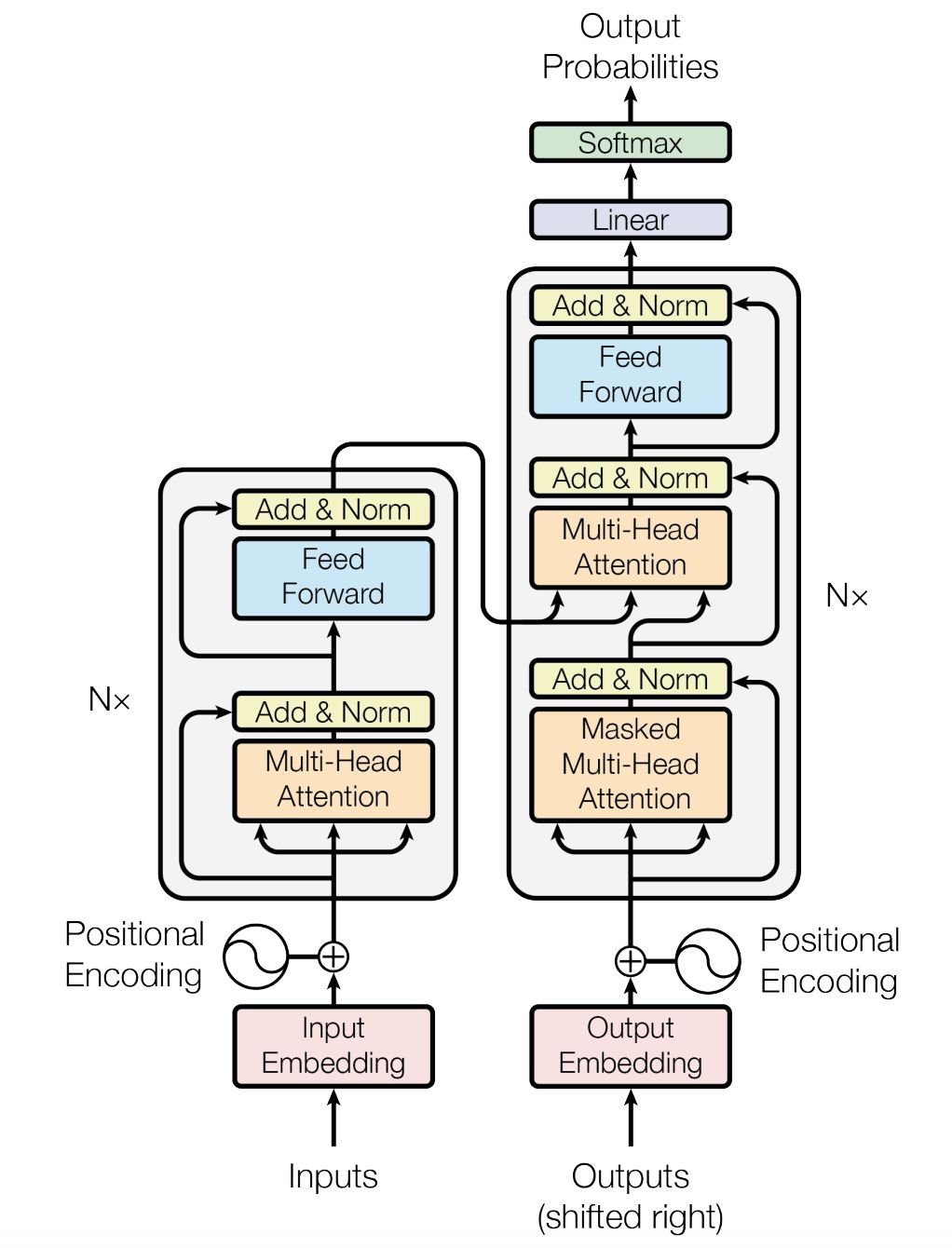
La partie à gauche représente l'encodeur, et la partie à droite le décodeur. Tous deux sont composés de modules qui s'enchaînent à plusieurs reprises (N fois dans le schéma ci-dessus). Comme on peut le voir, ces mêmes modules sont composés principalement d'un mécanisme d'attention suivi d'un réseau de neurones feed-forward.
Sans rentrer dans les détails techniques, la principale nouveauté est d'avoir construit un modèle qui se base principalement sur le mécanisme d'attention, sans RNN.
A Transformer-based approach to Irony and Sarcasm detection (2020)
Etant très sensible à l'humour sarcastique, j'ai trouvé cet article particulièrement intéressant. Il s'agit de détecter les figures de style, et plus particulièrement, le sarcasme, l'ironie et la métaphore.
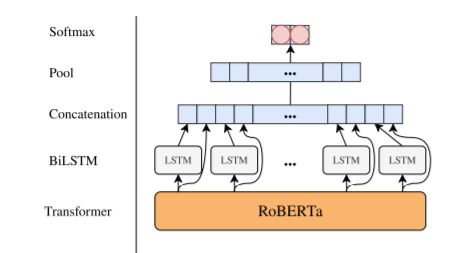
La solution proposée est une combinaison d'un modèle RCNN (réseaux neuronal convolutif récurrent) avec RoBERTa (Robustly Optimized BERT pretraining approach).
Une version améliorée de BERT est le modèle de représentation du langage publié par Google en 2019.
L'idée qui a stimulé ce modèle est issue de l'observation suivante : l'utilisation en amont d'un modèle pré-entraîné pour les tâches en NLP s'est avérée être très bénéfique, le résultat obtenu peut être amélioré s'il est traité correctement par les autres réseaux de neurones utilisés.
Ainsi RoBERTa pré-entraîné est utilisé pour transformer les mots d'un texte en un embedding très riche. Cela permet de récupérer les informations contextuelles. Puis dans le but de modéliser les relations de dépendance temporelle, les auteurs proposent l'utilisation d'un réseau de neurones récurrent auquel ils ajoutent une couche de neurones entièrement connectés afin de simuler un réseau neuronal convolutif avec un large noyau.
Le modèle RCNN-RoBERTa se révèle être meilleur que la plupart des modèles de l'état de l'art dans le domaine :
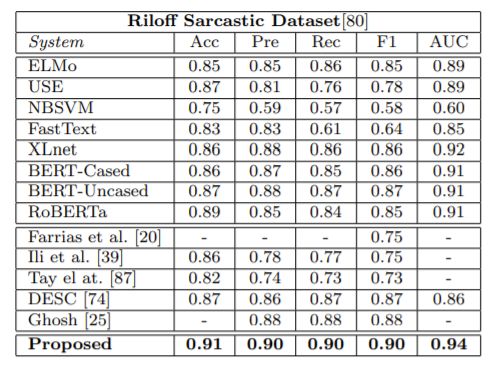
Source : RCNN-RoBERTa
An Image is worth 16x16 words: transformers for image recognition at scale (2020)
Inspiré du succès des transformers dans les tâches du traitement du langage naturel, les chercheurs ont commencé des travaux sur leur utilisation dans le domaine de la vision par ordinateur.
C'est en 2020 que Google Research publie le modèle Vision Transformer (ViT) avec des résultats venant concurrencer les modèles faisant état de l'art dans la reconnaissance d'images (notamment les réseaux neuronaux convolutifs).
Le principe utilisé est de diviser une image en plusieurs patchs, qui seront alors traités de la même manière que des mots. Les auteurs ont voulu se rapprocher au plus possible du modèle original des transformers, afin de pouvoir bénéficier du passage à l'échelle du modèle et de ses implémentations très performantes.
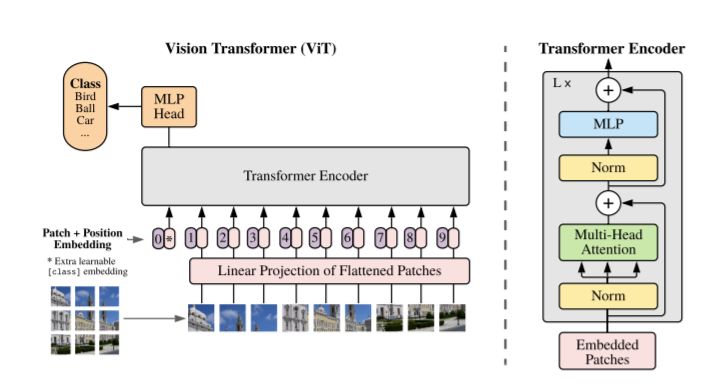
Ces patchs de tailles fixes vont alors être encodés par une couche d'embedding (ou de vectorisation). On ajoute à cette couche le positional embedding pour prendre en considération la position de chaque patch dans l'image.
L'embedding permet de représenter les données en entrée dans une dimension plus petite. Cela permet d'extraire une structure de nos données, par exemple, on peut s'attendre à ce qu'une voiture et un bus soient proches dans cet espace vectoriel.
Finalement, la classification est réalisée en utilisant un MLP (Multiple Layer Perceptron) composé d'une seule couche. La simplicité de ce modèle, face à sa performance m'a bien surpris.
Source : Vision Transformer
Generating Long Sequences with Sparse Transformers (2019)
Ce papier, publié par la fondation OpenAI, se concentre sur la génération de longues séquences.
Cela peut être la génération d'audio comme :
- de la musique,
- d'images afin de compléter une image (pratique pour retirer les personnes que vous n'aimez pas de vos photos),
- ou encore de texte, pour réécrire votre dernière anecdote avec le style de Shakespears.
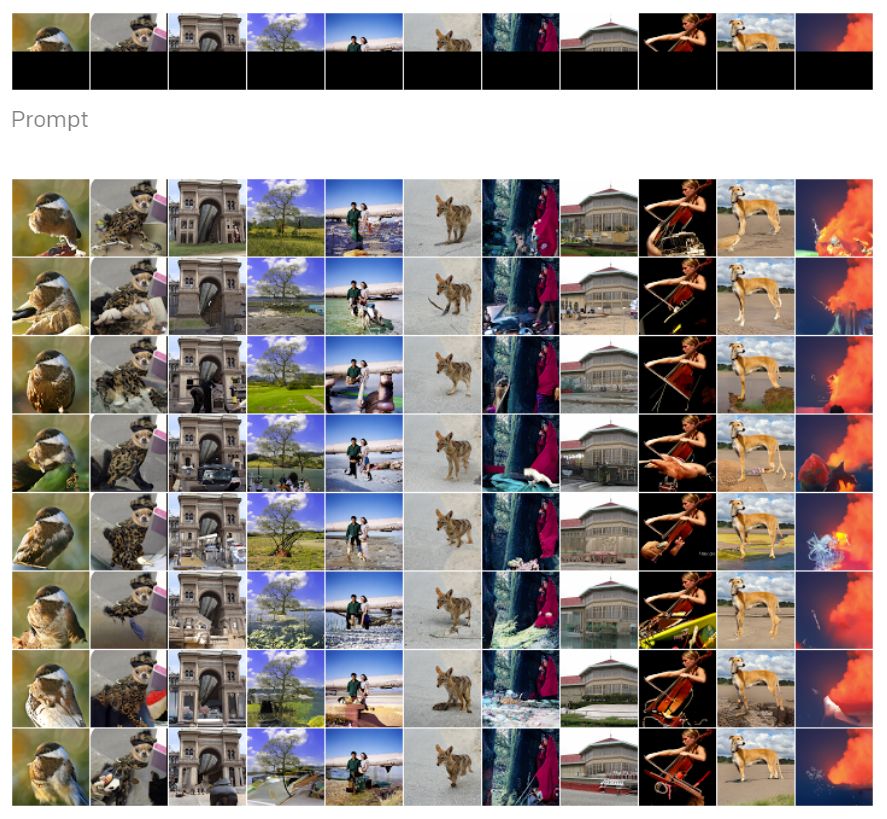
Il a été démontré que l'utilisation des transformers pour ce type de problème offre de bonnes performances. Néanmoins le mécanisme d'attention requiert le calcul de n poids pour chacun des n éléments. La complexité spatiale et temporelle des transformers est alors quadratique suivant la taille de la séquence.
Ainsi, l'idée principale de cet article est d'introduire la factorisation en matrice creuse de la matrice dite d'attention afin de réduire cette complexité en O(n√n).
De plus, d'autres modifications sont apportées dans le but d'optimiser le modèle, notamment le calcul de la matrice d'attention durant la phase de rétropropagation du gradient, qui permet de gagner en espace mémoire.
Cela donne lieu aux "Sparse Transformers", qui démontrent la possibilité de modéliser des séquences de dizaines de milliers de pas de temps avec une centaine de couches de neurones (ce qui n'était pas possible avant au vu des performances des équipements modernes).
Il est intéressant de noter que la même architecture est utilisée pour modéliser des images, de l'audio ou du texte. Les résultats obtenus donnent des échantillons avec une grande diversité et présentant une certaine cohérence dans la globalité.
Source : Sparse Transformers
Conclusion
Finalement depuis leur publication en 2017, la communauté de la data science s'est appropriée les transformers qui n'en finissent pas de nous surprendre. Leur place dans l'intelligence artificielle est de plus en plus grande, et les dernières publications ne parlent que d'eux (la Petite Marie des data scientists).


